Nieuwe feature Chain Fill: data matching en opschoning met AI

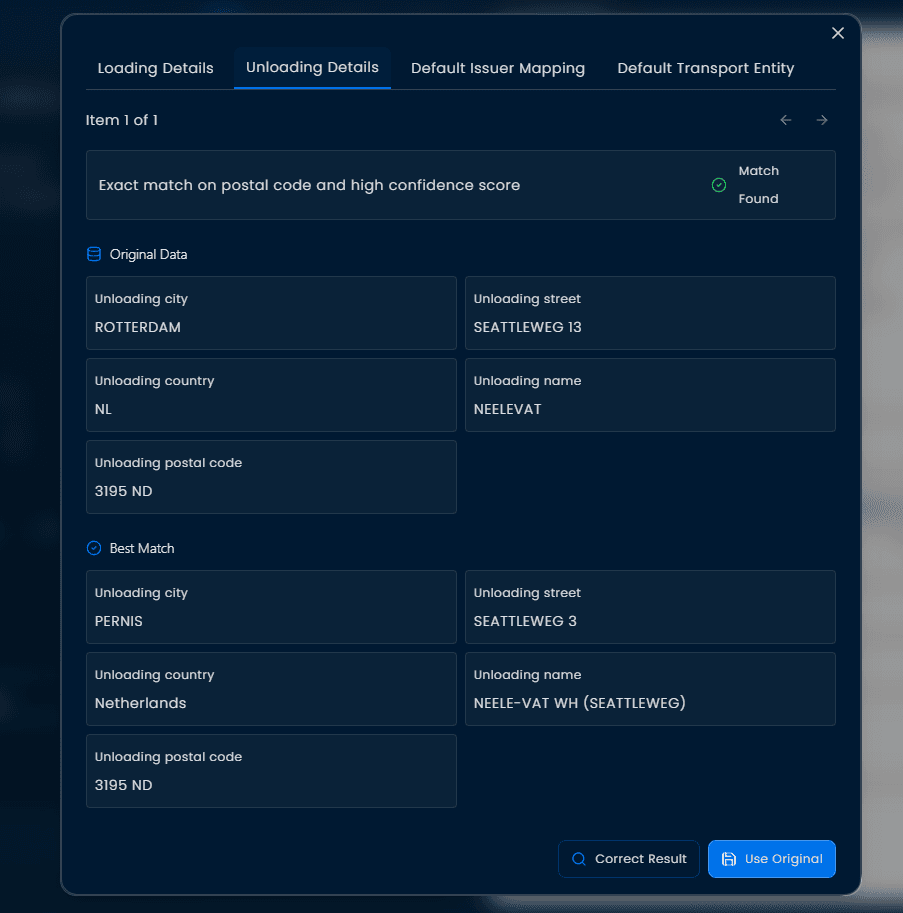
De afgelopen tijd hebben we ons gefocust op een veelvoorkomend probleem: Het matchen van nieuwe met bestaande data. Dit is essentieel om datakwaliteit te behouden en duplicaten te voorkomen.
We zagen dat het een terugkerend probleem was: rommelige data. Daarom hebben we snel dit probleem opgepakt. Op het platform kan je nu gemakkelijk je datasets inladen en worden duplicaten gefilterd om de dataset op te schonen. Elke keer als er een nieuwe order binnenkomt, checkt een AI model te huidige database, geeft de entries een score, en matcht dan de passende entry met de data van de order. Zo zorgen we ervoor dat er geen duplicaten in het TMS komt.
Hetzelfde principe kunnen we eigenlijk met alle variabelen toepassen! Wel zo makkelijk, aangezien veel transportbedrijven hun eigen gebruiken hebben. Bijvoorbeeld: Bedrijf A noemt een pallet: pal, terwijl bedrijf b een pallet pallet(s) noemt. Het is essentieel dat dit goed gekoppeld is, omdat er vaak facturatie flows hangen aan deze benamingen, en misschien nog belangrijker: de planners associëren specifieke benamingen aan afmetingen.
Al met al zijn we erg blij met deze update, maar vooral ook onze gebruikers. Zo komen we stap voor stap steeds verder in het optimaliseren van het order proces! En er ligt nog meer in het verschiet: Hou ons de komende tijd goed in de gaten, want het wordt alleen nog maar beter!